When I was moving to the DC area in early 2025, my apartment search was plagued by luxury highrise buildings with tons of fake reviews, algorithmic pricing, and hidden fees. We toured a couple, but honestly I was so exasperated by their deceptive practices that I decided to say screw it and only look at small, independent landlords.
Searching Zillow
For whatever reason, Zillow seemed to be the best platform to look for these types of apartments. Maybe because people who buy and sell rental properties are familiar with the platform, so they also list them for rent there?
I was hopeful I would be able to apply some filter options to show only the smaller buildings, but for some reason this feature is totally missing from Zillow. You can select certain home types, but this wasn’t useful to me. Unfortunately lots of duplexes and smaller apartment buildings are listed as “apartments” alongside the big highrises. I didn’t want to limit myself to only renting houses or townhomes, which tended to be a little out of my price range.
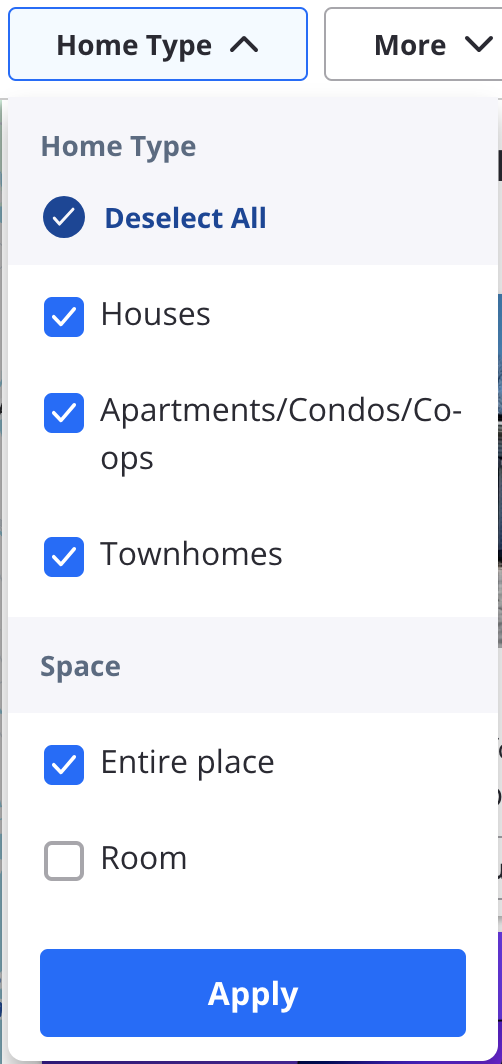
They also have this filter option for apartment communities, which turned out to be the exact opposite of what I was looking for. I want to hide these “communities” but there’s no way to inversely check this box. It seemed like I would have to figure this out myself.

Editing URL Params
I wondered if I could do a little light hacking and modify the URL to include the filter I wanted, since it seemed like all the other filters were included as URL params. I pulled up both a regular search and one with the “communities” filter applied and copied the URLs.
After pasting the URLs into an online decoder, I could see a bunch of search params that were mostly meaningless to me. The two objects were almost identical, but with one difference. When the “communities” filter box is checked, it adds a value to filterState called "fmfb":{"value”:false}. I’m not sure why checking this box adds a false param, but this was definitely what I was looking for.
https://www.zillow.com/homes/for_rent/?searchQueryState={"isMapVisible":true,"mapBounds":{"west":-77.08456537521572,"east":-77.03984758651943,"south":38.83129148648382,"north":38.86047064887117},"mapZoom":15,"filterState":{"sort":{"value":"personalizedsort"},"fsba":{"value":false},"fsbo":{"value":false},"nc":{"value":false},"cmsn":{"value":false},"auc":{"value":false},"fore":{"value":false},"pmf":{"value":false},"pf":{"value":false},"fr":{"value":true},"fmfb":{"value”:false}},”isListVisible":true,"pagination":{},"usersSearchTerm":"","listPriceActive":true}
My hope was I could just flip this value to true and the search filter would exclude these highrises. Sadly, after manually editing the value and re-encoding it, navigating to the URL just showed me a regular search with both small and large complexes visible. There must be some backend validation happening, since it simply ignored my true value as if fmfb wasn’t there.
Scraping Zillow
My next idea was to scrape all of the properties both with and without the communities filter on, then subtract the second set from the first set. This should give us the properties that don’t appear when the communities filter is on.
I found a couple of semi-abandoned open source Zillow scraping projects online, but I didn’t have a lot of faith in them. I really didn’t want to get my account banned, and I figured Zillow probably has a lot of anti-scraping and anti-automation measures on their site considering how valuable real estate data is.
Plus, I was only looking at a relatively small number of places (around 800 total options, after applying some basic filters for price, bedrooms, and location) so I didn’t think full-fledged automation was necessary. It would probably be simpler to just view each search page manually and use my browser’s devtools to capture whatever JSON the Zillow APIs were sending.
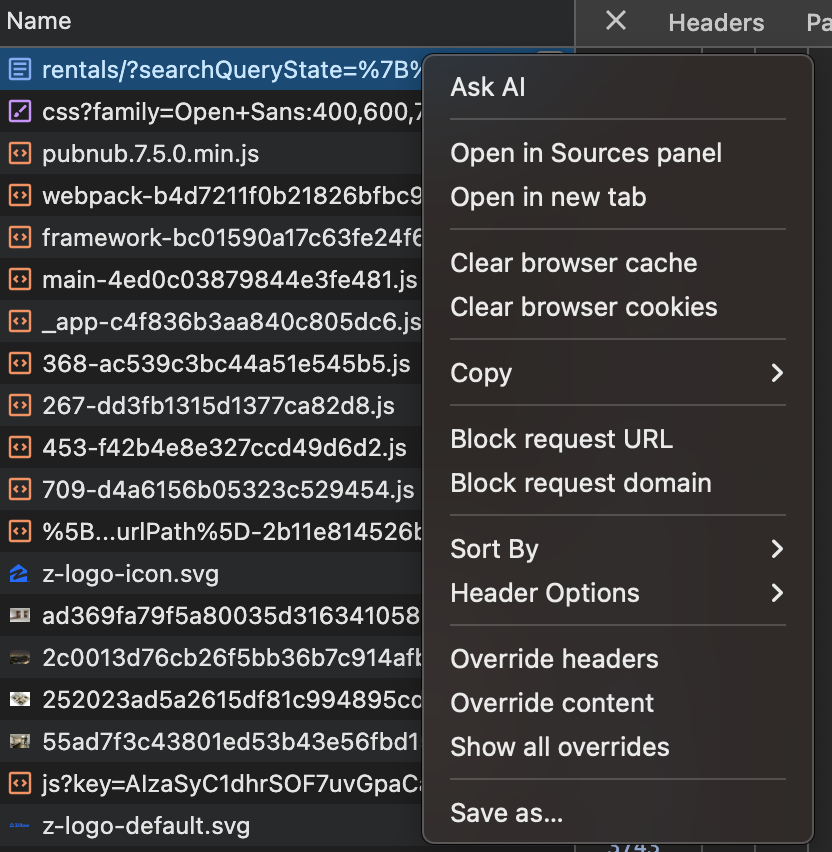
The First Page
Zillow paginates its search results, so the 800 or so properties would show up across several pages. I thought each page would just be its own fetch request to get some JSON from the API, but the first page was different. When you initially load a Zillow search page, it loads a large HTML file that contains that first page’s data all within a <script> tag.
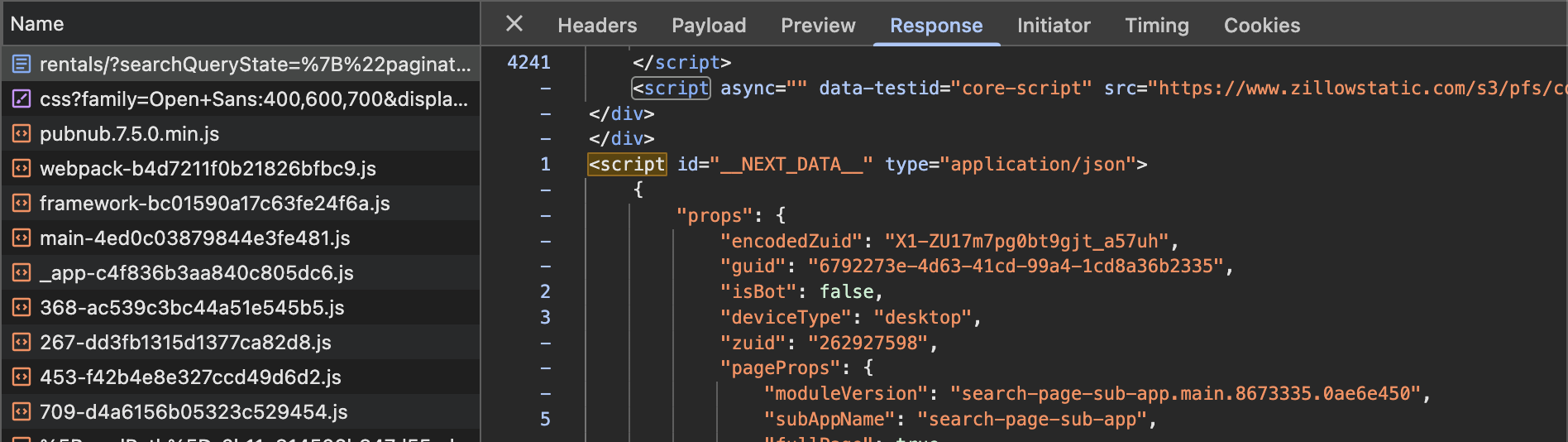
Later Pages
When you click on the next page button, it does hit the API and returns a JSON blob. The later page data is stored in a request called async-create-search-page-state. These two JSON objects contained some various extra bits of info that weren’t consistent between the two, but the actual search results data seemed to be stored under the listResults key in both cases.
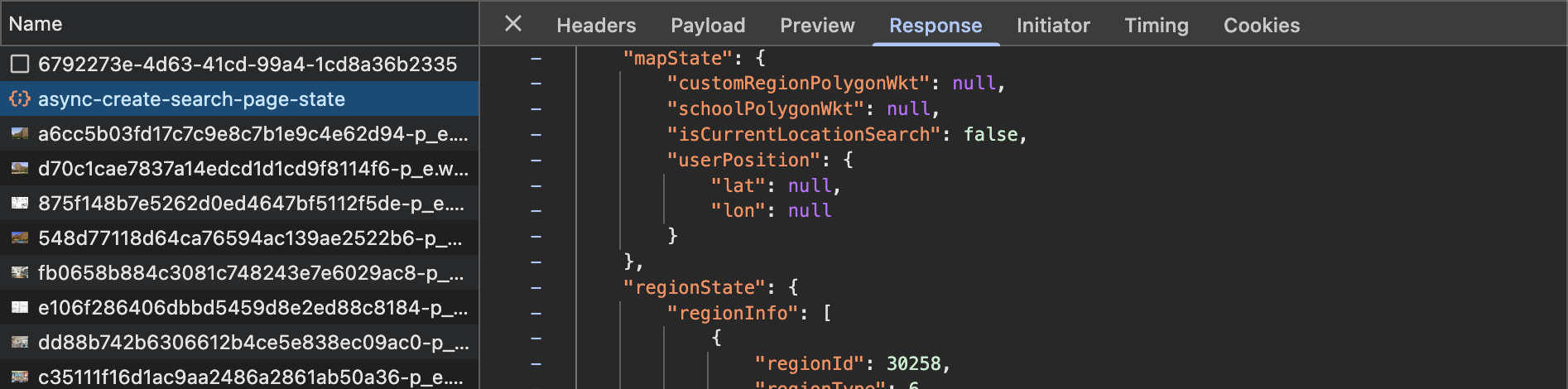
Since the search data itself was formatted the same between the two, I decided to write a parser that could handle both an HTML and JSON file and spit out the JSON of just the search data.
Extracting JSON
The data we care about is contained between the opening and closing brackets immediately after the listResults string in our files. Initially I tried manually counting characters one by one, but unsurprisingly this didn’t perform well enough for even moderately large files.
Instead I resorted to using a StringScanner to extract our data. First, we skip to where we find the listResults: key in the file. The results sometimes had weird whitespace padding between various parts, hence the catch-all \s* in the regexp.
data = File.read(file)
scanner = StringScanner.new(data)
scanner.skip_until(/"listResults":\s*\[/)
Next, we count brackets to figure out where the array of search data ends. Every opening bracket adds one to our count, and every closing bracket subtracts. Our skip_until regex already captured the first opening bracket, so we start our count at one. Every opening bracket we encounter should have a corresponding closing bracket, so we continue in our loop until our bracket count returns to zero.
bracket_count = 1
while bracket_count > 0
case scanner.scan(/[^\[\]]+|\[|\]/)
when '['
bracket_count += 1
when ']'
bracket_count -= 1
end
end
If you aren’t a regex wizard, here’s the simple explanation. Brackets are a reserved character in regex, so when we want a literal bracket we have to escape it like \[. The first part of the regex [^\[\]]+ says: match one or more + characters that are not ^ an open or close bracket \[\]. The second and third part |\[|\] says: or | match exactly one open \[ or (again) | match exactly one closing \] bracket.
The scan function returns what string it matched, so in the case of a bracket we adjust our counts, and for other text (the actual data in the JSON) we just ignore it for now.
Of course, parsing HTML with regex doesn’t come without punishment. For some reason our scanner would sometimes skip a few characters past the end of the last bracket, even though bracket_count was at zero and the loop ended. I didn’t really feel like spending a lot of time debugging, so I just wrote a small manual backtracking loop1.
end_pos = scanner.pos
end_pos -= 1 while data[end_pos] != ']'
Now, we can snip out the part of the file that has the JSON we’re interested in, surround it in curly brackets (that’s how all JSON must be), and parse it directly.
start_pos = data.index('"listResults"')
json_array = data[start_pos..end_pos]
json_array.strip!
json_array = "{#{json_array}}"
parsed_results = JSON.parse(json_array)
In the full script I added some extra logic for error handling and logging to help me debug various parse issues I ran into. The full source code is linked at the bottom.
Finding Apartments
Since Zillow paginated the results earlier, each of our two searches (with and without the communities filter) consists of multiple saved files, which I placed in their own corresponding directories all-apts and community-apts. Now that we have our file parser, we just have to parse each of these files and combine the results. Ruby has a handy flat_map function that combines the arrays returned by parse_file() into one flat array, equivalent to doing .map{}.flatten(1).
all_apts = Dir.glob("all-apts/*.html").flat_map { |file| parse_file(file) }
We do this for both the all-apts and community-apts directories to get two different arrays. Then we filter out the apartments in all_apts by kicking out any elements that also exist in the community_apts array, which gives us our list of small buildings.
small_apts = all_apts.reject { |apt| community_apts.any? { |community| community["id"] == apt["id"] } }
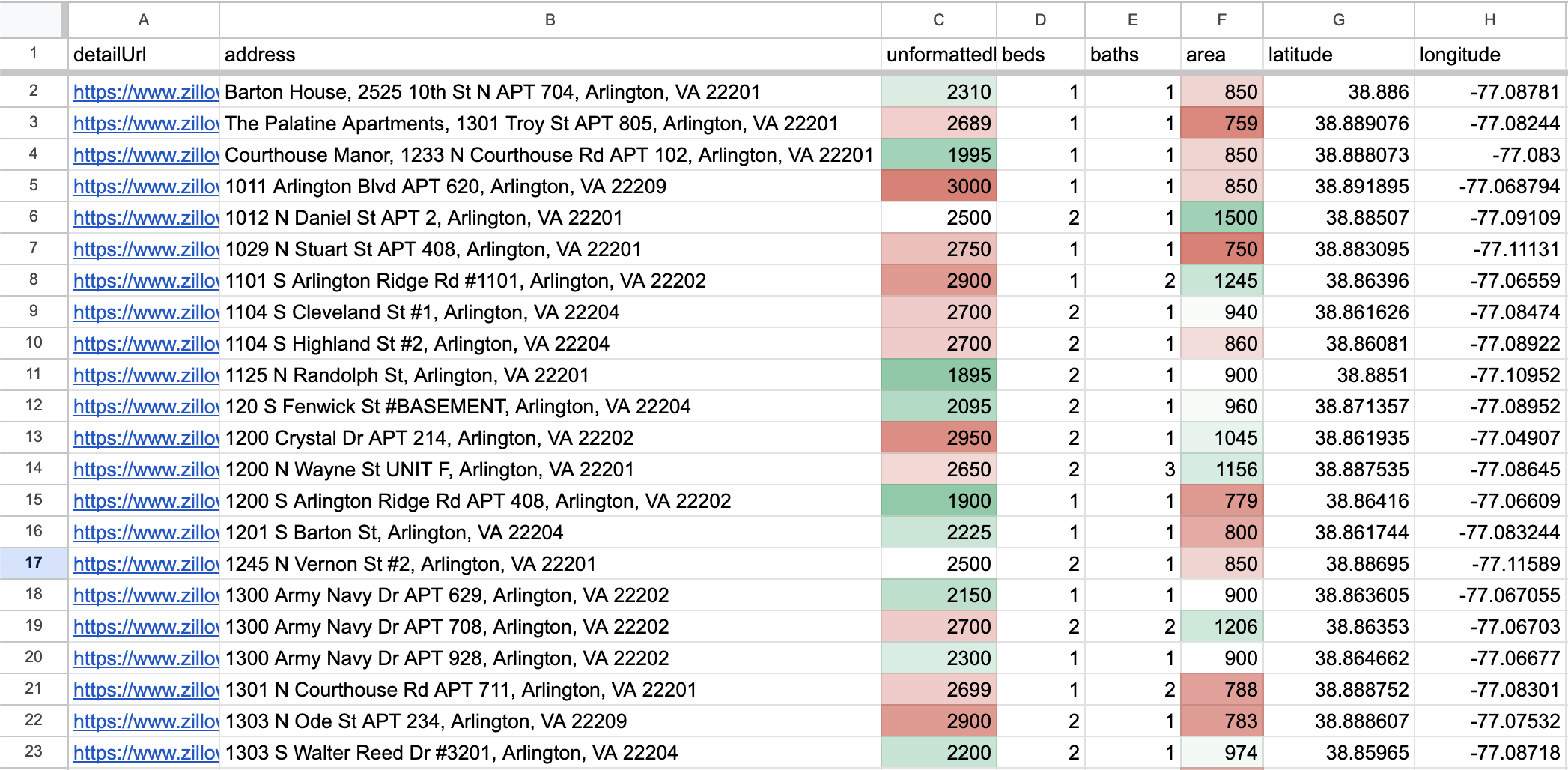
Exporting to CSV
The last thing is writing our data to a CSV file so I could create a nice color coded spreadsheet with sorting & filtering. Some of the entries were missing some fields, so I just skipped adding those to the CSV.
CSV.open('output.csv', 'w') do |csv|
csv << ['detailUrl', 'address', 'unformattedPrice', 'beds', 'baths', 'area', 'latitude', 'longitude'] # Header row
small_apts.each do |apt|
if apt['detailUrl'] && apt['address'] && apt['unformattedPrice'] && apt['beds'] && apt['baths'] && apt['area'] && apt['latLong'] && apt['latLong']['latitude'] && apt['latLong']['longitude']
csv << [apt['detailUrl'], apt['address'], apt['unformattedPrice'], apt['beds'], apt['baths'], apt['area'], apt['latLong']['latitude'], apt['latLong']['longitude']]
end
end
end
Look at that beauty! Out of nearly 800 options in the original search we ended up with 85 in our small apartment spreadsheet. Much better than going through all of that by hand. Ultimately, we used this sheet to find a couple places to tour and finally choose the perfect apartment for us.
-
I’m hoping this hacky solution is enough to invoke Cunningham’s law and get somebody to tell me what’s actually going on here :^) (return)